信息來源:Free Buf
我原本認為�,在聽音樂這件事上���,最不需要的就是提心吊膽了�。直到又一例隱藏惡意代碼的wav音頻文件曝光���,隱寫術的魔爪終于從png和jpg伸向wav文件���。

10月17日,BlackBerry Cylance威脅研究人員最新發(fā)現:wav音頻文件中嵌入模糊惡意代碼�。
播放時,你聽到的wav文件發(fā)出的音樂沒有明顯的毛刺或質量問題�,甚至還有點動聽。背地里���,音頻加載程序解碼并執(zhí)行音頻數據中的惡意代碼�,目標很清晰���,就是挖礦�。

無獨有偶�����,俄羅斯Turla也用過這一招����。今年6月,俄羅斯網絡間諜組織Turla就創(chuàng)意性地將惡意代碼隱藏在W**音頻文件中并傳輸至攻擊目標����,這也是全球首個用W**文件傳播惡意代碼的攻擊活動�����。有點不同的是����,人家Turla組織不挖礦����,而是用W**音頻文件發(fā)起的國家級攻擊活動,直接指向網絡間諜入侵����。
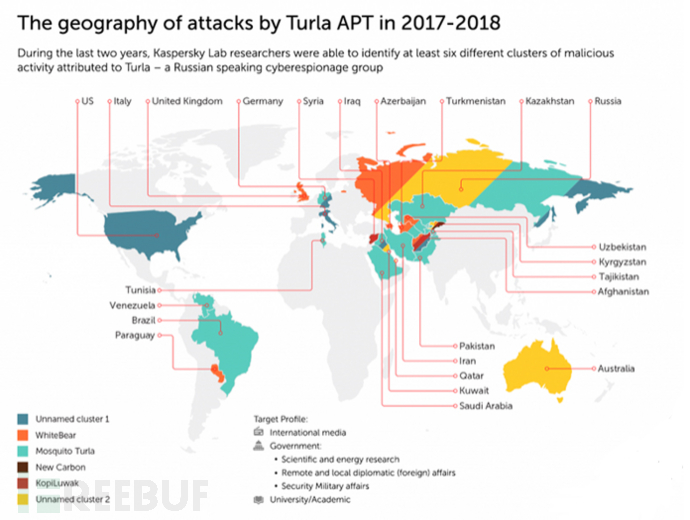
Turla組織顛覆了以往文本、圖片����、鏈接等形式的局限,拉開了用W**音頻文件傳播惡意代碼的大幕�。
繼Turla組織的間諜行動后,其他黑客也效仿了起來�。
BlackBerry Cylance所發(fā)現的是全球首例用W**音頻隱寫術加密挖礦的網絡攻擊�����。受感染主機在下載并使用特定wav加載程序加載W**文件后,會繞開電腦殺毒軟件與防火墻���,安裝XMRrig加密貨幣礦工應用程序���,變身“挖礦機”。
BlackBerry Cylance研究與情報副總裁還補充說�����,現在Windows桌面和服務器上都發(fā)現這種隱寫惡意代碼的W**文件����。簡言之,個人及企業(yè)用戶已暴露在了隱寫術加持下的惡意攻擊威脅中����。
什么是隱寫術?
安全員都知道�,隱寫術就是指將信息隱藏在另一種數據介質中的技術。例如���,將純文本隱藏在圖像中�����,又例如將惡意代碼隱藏在音頻中���。

這挺雞賊的�,因為通過這種手段����,暗藏惡意代碼的文件就可以躲開安全軟件的查殺攔截,甚至“洗白”享受白名單待遇����,長久潛伏而不被發(fā)現。
隱寫術在惡意程序開發(fā)中已經流行了十多年���,最近開始�����,隱寫術開始從PNG���、JPG圖片蔓延至W**音頻文件。
我們以BlackberryCylance披露的報告威力進行分析�,這類wav文件加載器可以分為以下三類:
1、采用最低有效位(LSB)隱寫術的加載程序解碼并執(zhí)行PE文件。
2����、加載程序采用基于rand()的解碼算法來解碼和執(zhí)行PE文件�。
3、加載程序采用基于rand()的解碼算法來解碼和執(zhí)行shellcode����。
第一類:隱寫術PE加載器
第一類加載程序采用隱寫術從W**文件中提取可執(zhí)行內容。
隱寫術是一種在另一個文件中隱藏文件或消息的做法�,一般情況下不會引起對目標文件的懷疑。攻擊者大量使用隱寫技術來隱藏數據����。
實際上,BlackBerry Cylance于4月發(fā)布了一份報告�,該報告描述了海蓮花組織如何利用隱寫術來隱藏圖像文件中的惡意后門。本文分析的樣本使用了最低有效位隱寫術(LSB)將惡意代碼隱藏在音頻文件中�����,其中單個字節(jié)的最右位包含惡意代碼����。
樣本信息如下:
技術細節(jié):
這個加載器讀取wav文件頭的最后四個字節(jié),這四個字節(jié)表示wav文件中存儲數據的大小,在這個惡意的wav文件里�,這個大小是15,179,552 字節(jié)。

圖:W**文件頭-數據大小
在下面的代碼片段中�����,加載程序讀取這四個字節(jié)�,并依此分配內存空間。然后�����,它讀取數據并關閉W**文件���。最后�����,do-while循環(huán)遍歷前64個字節(jié)���。按照下圖所示的算法進行解碼。
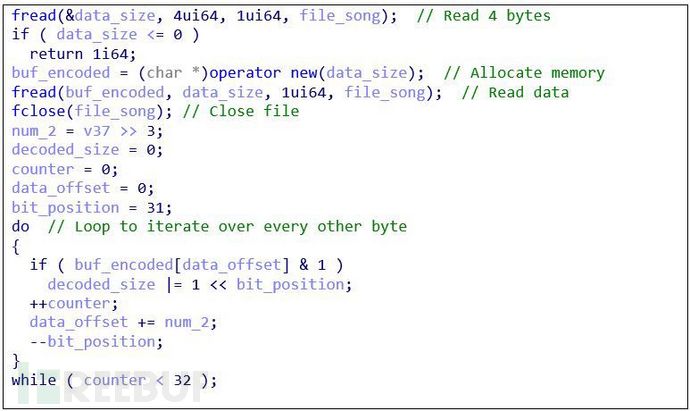
圖:解碼文件大小
顯而易見�,循環(huán)是在計數器<32且計數器每次迭代遞增1時執(zhí)行的。另外����,data_offset表示編碼數據內的偏移量�,其值每次迭代從零開始遞增2�。此循環(huán)將覆蓋數據的前64個字節(jié)(32* 2):
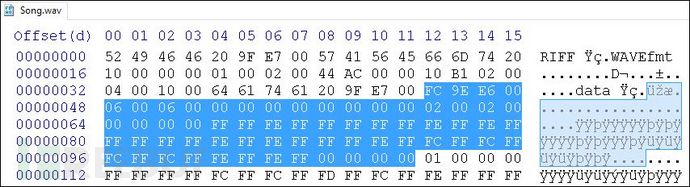
圖:W**文件數據-64字節(jié)
對于每個已處理的字節(jié),加載程序將提取LSB并將其分配給decoded_size中的相應位位置�����,從31(即最左邊的位)開始���,并在每次迭代時遞減1,并將此算法應用于數據的前64個字節(jié)���。
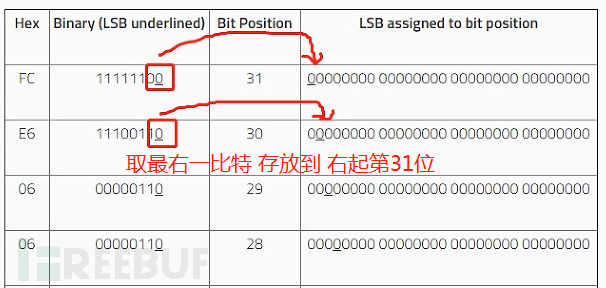
接下來���,分配大小為decoded_size的存儲器,并且執(zhí)行各種計算�。修改了默認標簽名稱,以指示所有計算的結果�����。這些數字將在即將到來的解碼循環(huán)中用作已編碼數據的偏移量:

圖:分配內存并計算偏移量
按照上面的代碼�����,do-while循環(huán)開始解碼其余的編碼數據:

圖:解碼文件內容
與前一個解碼循環(huán)類似,此循環(huán)提取每個其他字節(jié)的LSB�。但是,區(qū)別就在于它起始于最低位(最右一位)����。每次迭代都從8個字節(jié)中提取LSB,以形成8位(1個字節(jié))的解碼數據����。
如果應用此算法生成兩個字節(jié)的解碼數據,就需要32個編碼字節(jié)����。因為8位組成一個解碼字節(jié),并且每兩個編碼字節(jié)提取一個LSB���,所以生成兩個解碼字節(jié)就需要32個編碼字節(jié)(2個解碼字節(jié)*每個解碼字節(jié)8個LSB * 2 = 32):
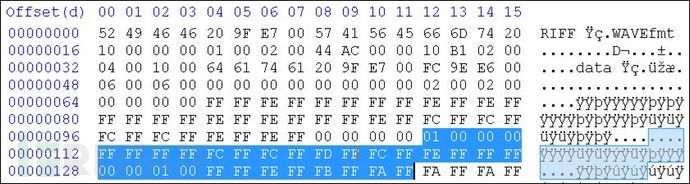
圖:32個字節(jié)的編碼數據
第二類 基于Rand()的PE加載程序
第二類加載器使用基于rand()的解碼算法來隱藏PE文件�����。
樣本信息如下:
技術細節(jié):
執(zhí)行后���,此加載程序將讀取W**文件頭����,提取數據大小���,相應地分配內存�,并將W**數據存儲在新分配的內存中���。接下來����,加載器解碼W**文件的數據內容:

圖:基于Rand()的PE加載器解碼循環(huán)
注意�����,size_of_data表示從W**頭中提取的數據大小���,wave_data包含編碼的W**數據的地址。加載程序調用srand函數和rand函數����,從W**數據中提取PE文件。
為什么選擇這兩個函數呢���?因為當srand函數接收一個固定的值作為種子的時候�,每次調用rand函數就會生成一個固定的偽隨機數。
此時���,do-while循環(huán)遍歷編碼數據的每個字節(jié)�����,用從編碼字節(jié)中減去rand()生成的偽隨機數替換該字節(jié)����。例如���,讓我們解碼此處顯示的數據的前兩個字節(jié):

使用本節(jié)分析的加載器和W**文件����,下表顯示srand()種子值為0×309的前兩次迭代的值:
|
循環(huán)運行
|
W**數據(字節(jié))
|
rand()輸出(低字節(jié))
|
區(qū)別
|
|
1
|
0x5C
|
0x0F
|
0x5C-0x0F = 0x4D
|
|
2
|
0×99
|
0x3F
|
0×99-0x3F = 0x5A
|
前兩個字節(jié)代表通常在PE文件開頭出現的“ MZ”����。循環(huán)遍歷所有數據字節(jié)后,就解碼出XMRig Monero CPU64位挖礦DLL�。生成的DLL與Song.wav解碼的DLL僅相差四個字節(jié):


圖:解碼后的click.wav與Song.wav
雖然不清楚這些字節(jié)為何不同,但是它們對DLL的功能沒有影響�����,因此這兩個XMRig DLL文件實際上是相同的。
接下來����,加載器獲取在命令行中指定的導出函數地址。如果存在���,則加載器將啟動一個線程來執(zhí)行它:
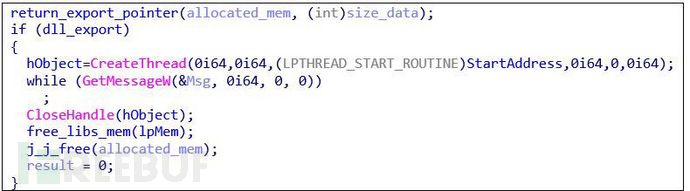
圖:確定導出和啟動線程的地址以執(zhí)行它
第三類:基于Rand()的Shellcode加載器
此方式和上述的方式及原理完全相同,不同點僅僅是前者加載的PE文件而后者加載的Shellcode
零日反思
網絡威脅的演進�,從來都是多維立體的����。
隱寫術從文本、圖片擴散至音頻���,就是最直觀的例子。
而隱寫術+惡意代碼+音頻多種形式融合的網絡威脅手段�����,也不斷提醒著我們���,網絡空間威脅會越來越復雜�,單純的攻防策略已難以有效守護網絡空間的一片安寧。